Gouge Away
in Big Data

You have just completed setting up your new and shiny EMR cluster, and want to unleash the full power of Spark on the nearest data-source.
All you need to do, is pass the location of the data in your S3 Bucket and employ the parallel capabilities of HDFS.
However, all your data is stored on a MySQL database.
One thing you can do is read the data with Spark and a JDBC connector from the database to a Spark Dataframe:
This is nice, but there is a better way!
This post comes after trying several approaches to get the easiest, cleanest, scalable and best performing data ingestion solution for the case of data stored on a MySQL server.
The goal of this post is to provide an easy and comprehensive, step by step, guide, on how to use Sqoop and incorporate it to your EMR job flow.
You can find a a walk-through on how to setup and launch an EMR cluster here.
In this post we will start with a brief introduction to Sqoop, continue with formulating the problem, go over the necessary tools and finally describe the proposed solution.
Small disclaimer - an active AWS account is necessary for this tutorial.
What is Scoop
Apache Sqoop (SQL to Hadoop) is a tool designed for efficient transfer of data between Apache Hadoop and structured data-stores (in our case - relational databases).
We will only scratch the surface on architecture of Sqoop, and briefly explain the import processes in high level.
Sqoop automates most of the data transfer, relying on the database to describe the schema for the data to be imported. Sqoop uses MapReduce to import and export the data, which provides parallel operation as well as fault tolerance.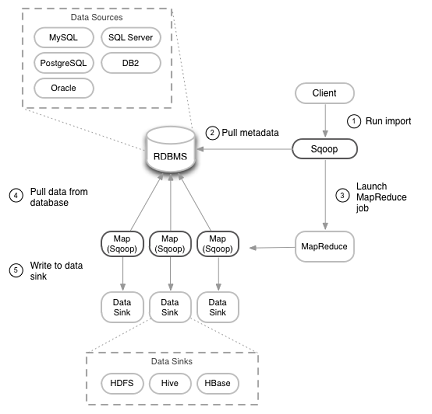
The import procedure (as described in the diagram above) goes through the following steps:
- Scoop (client) pulls the metadata from the database.
- Launches several MapReduce jobs.
- Each MapReduce job pulls its share of data from the database.
- Each MapReduce job writes the data to its target location.
Later we will show how to configure the number of MapReduce jobs to best fit the number of connections to the database.
Problem Formulation
The problem that we are facing can be broken down into 3 (as always) sub-problems:
- Spinning up a cluster with all the relevant dependencies.
- Connecting to a MySQL server and fetching the data with Sqoop.
- Storing the data.
Tools Description
In our solution we will use the following tools:
- Apache Spark - an open-source distributed general-purpose cluster-computing framework.
- Sqoop - a tool designed to transfer data between Hadoop and relational databases.
- Pyspark - the Python API for Spark.
- EMR service - Elastic Map Reduce is AWS managed Hadoop framework.
- S3 service - AWS storage service.
- Boto 3 - Boto is the AWS SDK for Python. It enables Python developers to create, configure, and manage AWS services.
Solution Formulation
In my previous post we have seen how to spin up an EMR cluster, pull the data from a MySQL server (using Spark) and load it to S3.
We will use the same code, and only swap the “extract_data_from_db” method with “extract_data_from_db_with_sqoop”.
Another thing you will need to do is add {‘Name’: ‘Sqoop’} to the applications list (in the load_cluster method in the EMRHandler class)
Applications=[{'Name': 'Spark'}, {'Name': 'JupyterHub'}, {'Name': 'Hive'},{'Name': 'Sqoop'}]
Our solution (as in the previous post) is broken down to 3 main scripts and a configuration file.
- EMR Handler - the python script that is in charge of spinning-up, configuring and running the EMR cluster.
- Bootstrap - this script is used to configure each node in the cluster.
- Processing - the python script that executes the data processing commands.
As stated, the solution is identical to the one described in the previous post apart from extracting method.
In the extract_data_from_db_with_sqoop method we are using the os.system(sqoop_command) command to execute the Sqoop import command.
It is comprised of the following parameters:
- driver - the MySQL driver
- connect - the database url
- username and password - the credentials for connecting to the database
- query - the query of the extracted data
- num-mappers - the number of mappers (for each node) that will fetch the data
- split-by - the column on which the mappers divide among themselves the workload
- target-dir - the destination of the transfered data
- –as-parquetfile - a flag indicating the format of the extracted data (parquet file in our case)
Several important points:
- As you can see, we are saving the data and then reading with Spark the parquet file and returning the Dataframe.
- I have made several attempts to extract the data to a S3 bucket without success (EMR release 5.22.0) - this should probably be fixed in later releases.
- The bigger the number of mappers you allocate - the faster the extraction be completed. However, you should not exceed the number of database connections.
Conclusion
In this tutorial we have gone through the steps needed to spin-up an EMR Cluster, read the relevant data from a MySQL database, and finally load the results to S3.
I hope this guide helped shed some light on how to use EMR and Sqoop to achieve the relevant results.